


Let's understand Hashing
Hashing is a unique algorithm crucial for maintaining security in any data system. Blockchain uses a hashing algorithm called (Secure Hash Algorithm), SHA-256 algorithm which converts any data given to it into 64 hexadecimal characters, wherein each character is of 4 bits. Thus, making it 256 bits in total.
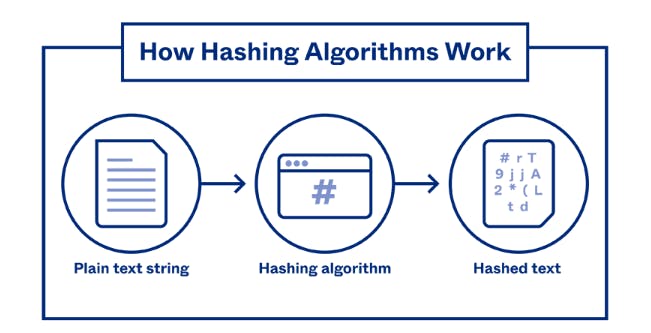
Hashing in Blockchain
It dramatically reduces the size of the file. One such practical use case is in maintaining the Blockchain network. As we can see below, this is a simplistic view of what's present inside a block in the blockchain. Storing data inside a blockchain is expensive. Also, block data is inversely proportional to scalability. Thus, to reduce the overall block size we adopt hashing the block and then storing it in the blockchain network.
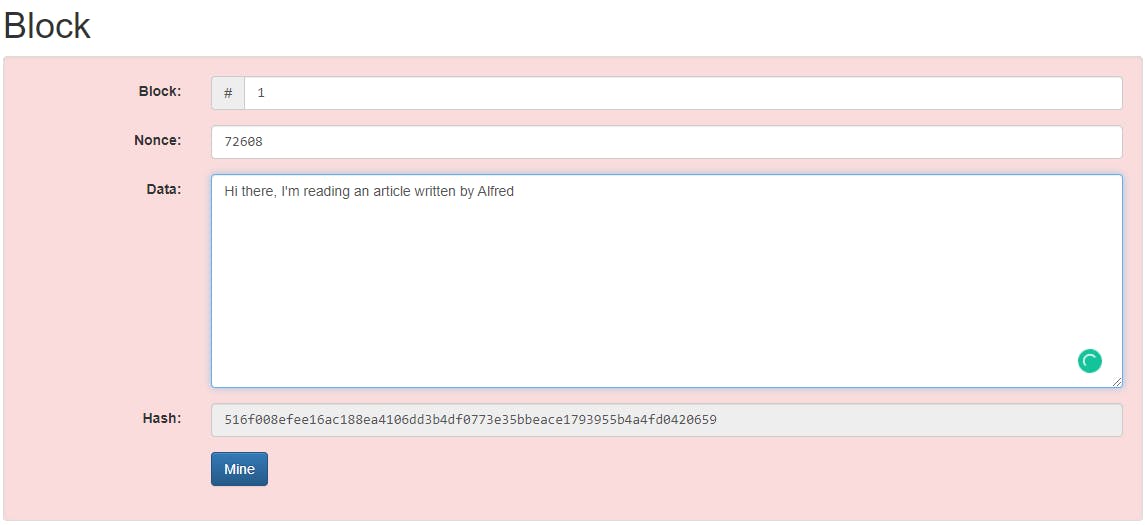
Each block is unique by the hash value given to it, and to make it a chain of blocks, we need something unique that links both the blocks maintaining zero compromises in security. This secure structure is achieved by the hash value of the block.
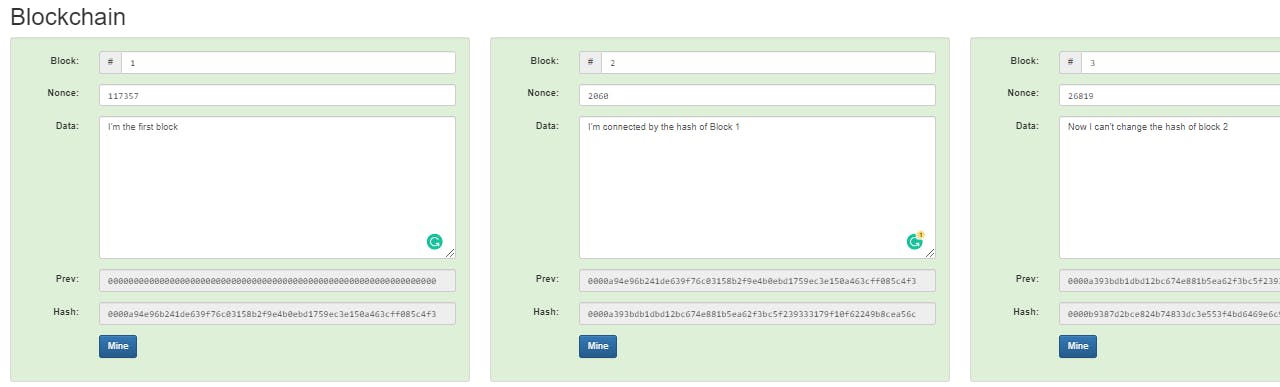
We can clearly see that each block is linked to the previous block by this unique hash and so on. Any data tampering efforts in any of these blocks result in a change in the hash value. This disrupts the continuity of the blocks in the blockchain. Blockchain has implemented a rule where each node adopts the longest chain and therefore agrees on the same transaction history. This approach denies block access to the attacker.
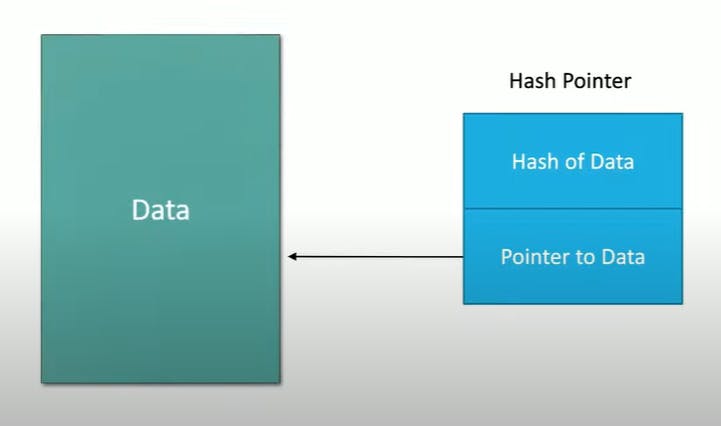
Hash Pointer -
Generally, the pointer stores the memory address of a particular data. A hash pointer on the other hand stores both the data and the cryptographic hash associated with it. This makes a hash pointer point to the data and also allows us to verify the data.
Why Hashing?
Saves time
Let's assume we need to store a large amount of data and perform various operations on it. When we perform a linear search or a binary search the time complexity is 0(n) and 0(log n) respectively. So, as the size of input data increases, these complexities become significantly high and slow down the process of data retrieval. To solve this, we need a search mechanism where searching is not affected by the input data size. Here's where hashing comes to the rescue. It allows time complexity to occur in a constant time.
Saves space
Each transaction in a blockchain contains the number of fields as shown. Larger the block size more are the number of transactions stored inside it, and this results in more time taken to add the block to the blockchain (basically a copy to all other nodes). To reduce the size of the block we hash it and store in a special data structure called Merkle Tree.
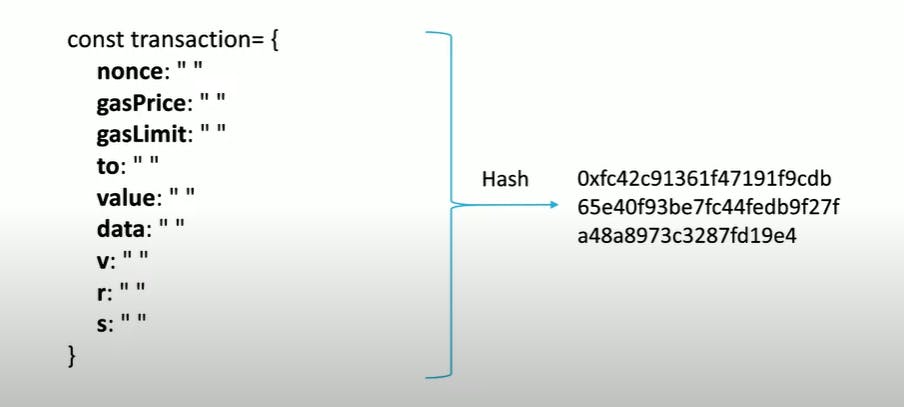
Merkle Tree -
It is used primarily for data verification and synchronization. It makes it easier to find data on a particular block. It is efficient in distributed systems where the same data is stored in multiple nodes. The Merkle tree is significant as it allows users to verify a specific transaction without downloading the whole blockchain which is around 350 gigabytes as of June 2021.
Working of Merkle Tree -
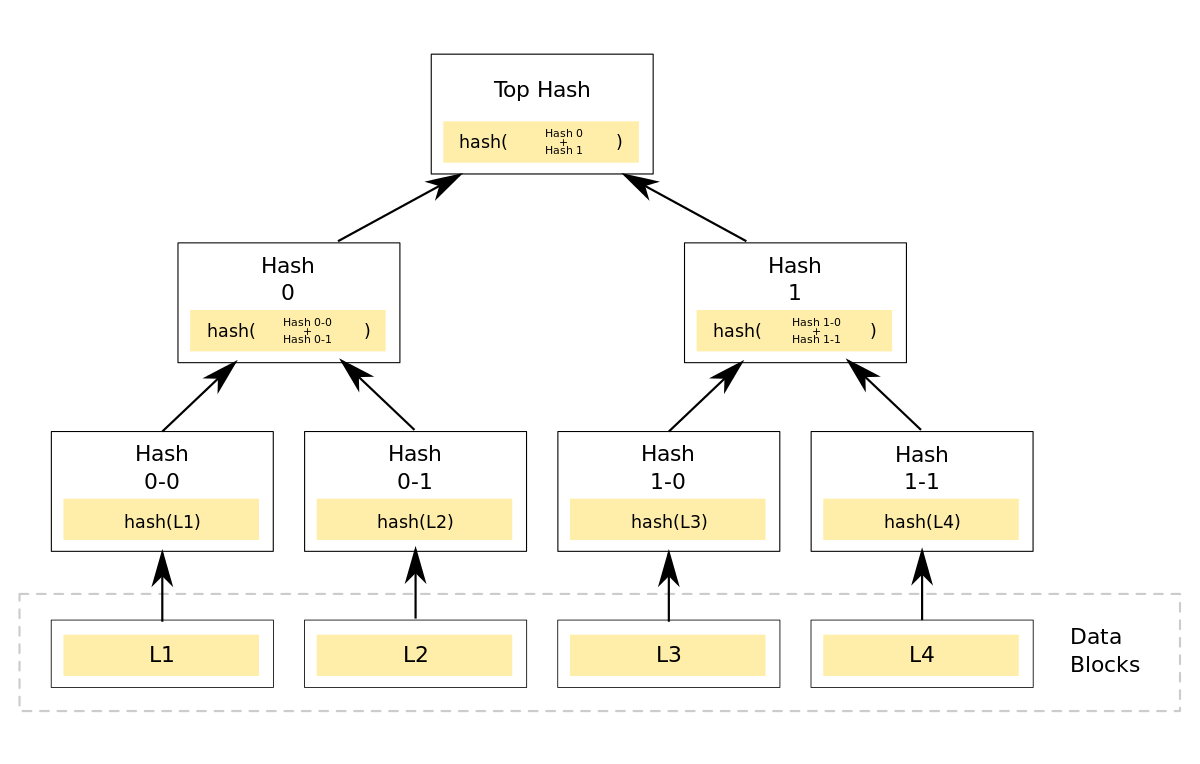
Here, let's assume L1, L2, L3 and L4 are 4 different blocks connected in a blockchain. The hashes on the bottom row are referred to as "leaves," the intermediate hashes as "branches," and the hash at the top as the "root." The merkle tree data structure is more like a bottom-up approach which connects the hashes of all the blocks. The Merkle root of a given block is stored in the header: for example, the Merkle root of block #L1 is e045b18e7a3d708d686717b4f44db2099aabcad9bebf968de5f7271b458f71c8. The root is combined with other information (the software version, the previous block's hash, the timestamp, the difficulty target, and the nonce) and then run through a hash function to produce the block's unique hash: 000000000000000000bfc767ef8bf28c42cbd4bdbafd9aa1b5c3c33c2b089594 in the case of block #L1.
Pros of Merkle Tree -
- Efficient verification of transactions
- Rapid data retrieval
- Lesser storage
- Tampering Detection